In our last post, we have refactored a sample application to be spot ready. Then we ran its entire stack on spot instances. However, one caveat is if particular spot instances were temporary not available in the market, we would fail back on demand instances in autoscaling group. It’s perfectly okay, but we are going to take cost optimization to the next level. In this post, we will introduce how to improve cost optimization Spot Fleet + autoscaling and also achieve high availability.
We did lots of work to convert everything into docker, now it’s time to reap the effort. A better cost optimization solution is AWS Spot Fleet. Spot Fleet is a request for a collection of spot instances. It also attempts to maintain its target capacity fleet if your Spot instances are interrupted due to a change in Spot prices or available capacity. Instance flexibility is the key to leverage Spot Fleet to maintain a target capacity. As you may remember, we have talked about instance flexibility in the past. It’s really important because you can use “unpopular” instances in the spot market to replace “popular” instance in any time frame to maintain your target capacity.
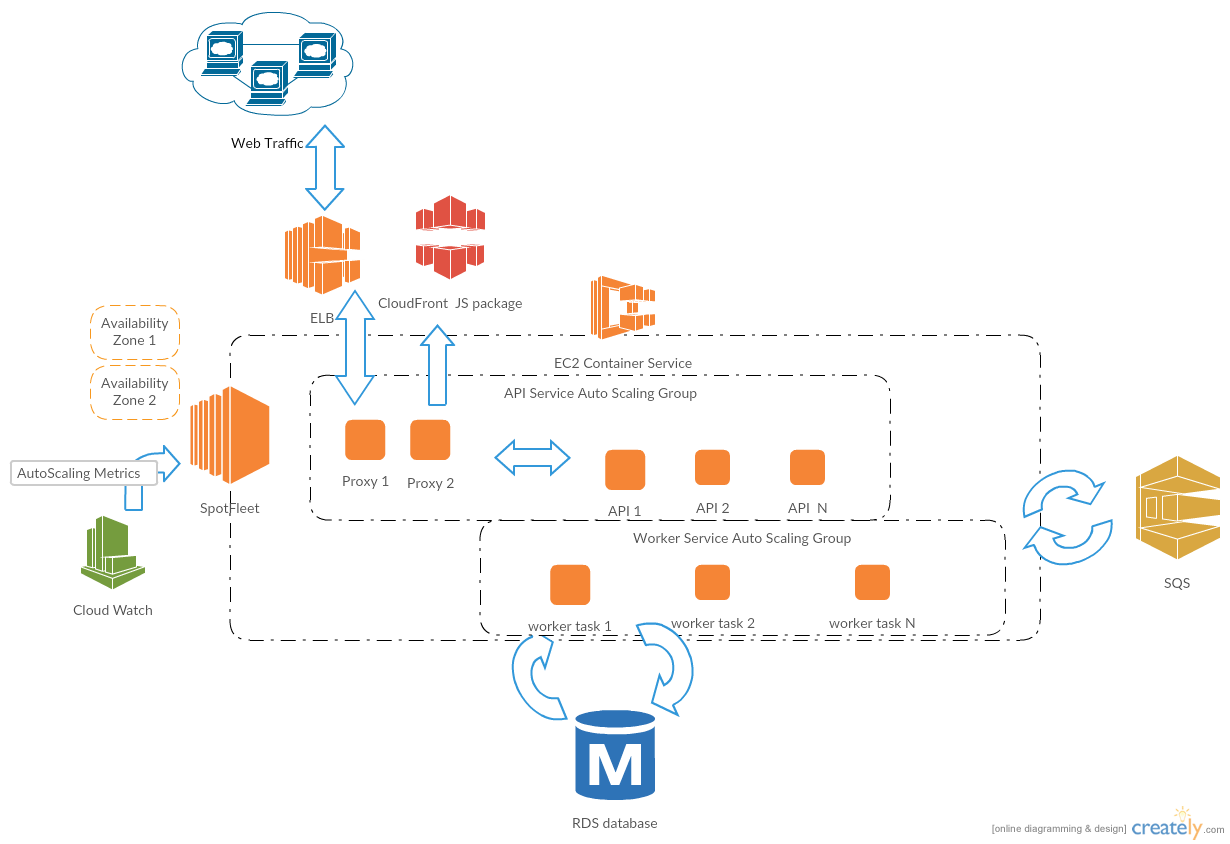
Let’s use our previous application as example. Instead of request one time spot instance in the autoscaling group, we are going to use Spot Fleet. Luckily, AWS has announced autoscaling group for spot fleet in the 2016 Sep. The cloudformation should look like this:
SpotFleet:
Type: AWS::EC2::SpotFleet
Properties:
SpotFleetRequestConfigData:
IamFleetRole: !GetAtt IAMFleetRole.Arn
SpotPrice: !Ref 'EC2SpotPrice'
TargetCapacity: !Ref 'DesiredCapacity'
TerminateInstancesWithExpiration: false
AllocationStrategy: lowestPrice
LaunchSpecifications:
- InstanceType: c3.large
...
- InstanceType: c3.xlarge
...
As you may notice we have specified two launch configuration set in Spot Fleet request example. In a real scenario, we should specify as many launch configuration as we could, that’s the power of instance flexibility. We don’t really care what instance type it is, because most of instance type can join ECS cluster. Though listing many launch configuration can be painful, here is a interesting approach from us – Programmatic Cloudformation Template.
Next thing is to add autoscaling group to cope with spike traffic and resource consumption. There are two level of autoscaling. One is at container level and the other is at ECS cluster level. Don’t worry we were confused at the beginning. Here is how it works. Let’s assuming SQS queue number is our scale measurement metrics. It would first scale up number of worker container if SQS queue backup. In any case, the ECS CPU has been utilized more than 70% , then it will scale up the number of spot instance in ECS to keep it overall CPU utilization under 70%. When the SQS queue drop down, it would scale down number of worker container. If the ECS CPU utilization has dropped lower than 30%, it will scale down the number of spot instances until minimum capacity. Following code are for autoscaling.
apiServiceScalingTarget:
Type: AWS::ApplicationAutoScaling::ScalableTarget
DependsOn: apiService
Properties:
MaxCapacity: 4
MinCapacity: 1
ResourceId: ...
RoleARN: !GetAtt [AutoscalingRole, Arn]
ScalableDimension: ecs:service:DesiredCount
ServiceNamespace: ecs
apiServiceScalingPolicy:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
PolicyName: AStepPolicy
PolicyType: StepScaling
ScalingTargetId: !Ref 'apiServiceScalingTarget'
StepScalingPolicyConfiguration:
AdjustmentType: PercentChangeInCapacity
Cooldown: 60
MetricAggregationType: Average
StepAdjustments:
- MetricIntervalLowerBound: 0
ScalingAdjustment: 200
workerServiceScalingTarget:
Type: AWS::ApplicationAutoScaling::ScalableTarget
DependsOn: workerService
Properties:
MaxCapacity: 4
MinCapacity: 1
ResourceId: ...
RoleARN: !GetAtt [AutoscalingRole, Arn]
ScalableDimension: ecs:service:DesiredCount
ServiceNamespace: ecs
workerServiceScalingPolicy:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
PolicyName: AStepPolicy
PolicyType: StepScaling
ScalingTargetId: !Ref 'workerServiceScalingTarget'
StepScalingPolicyConfiguration:
AdjustmentType: PercentChangeInCapacity
Cooldown: 60
MetricAggregationType: Average
StepAdjustments:
- MetricIntervalLowerBound: 0
ScalingAdjustment: 200
DemoALB500sAlarmScaleUp:
Type: AWS::CloudWatch::Alarm
Properties:
EvaluationPeriods: '1'
Statistic: Average
Threshold: '10'
AlarmDescription: Alarm if our ALB generates too many HTTP 500s.
Period: '60'
AlarmActions: [!Ref 'workerServiceScalingPolicy']
Namespace: AWS/ApplicationELB
Dimensions:
- Name: ECSService
Value: !Ref 'apiService'
ComparisonOperator: GreaterThanThreshold
MetricName: HTTPCode_ELB_5XX_Count
FleetCPUAlarmScaleUp:
Type: AWS::CloudWatch::Alarm
DependsOn: DemoCluster
Properties:
EvaluationPeriods: '1'
Statistic: Average
Threshold: '70'
ComparisonOperator: GreaterThanThreshold
AlarmDescription: Alarm if target instance CPU is overloaded
Period: '60'
AlarmActions: [!Ref 'FleetScalingUpPolicy']
Namespace: 'AWS/ECS'
Dimensions:
- Name: ClusterName
Value: !Ref 'DemoCluster'
MetricName: CPUUtilization
FleetCPUAlarmScaleDown:
Type: AWS::CloudWatch::Alarm
DependsOn: DemoCluster
Properties:
EvaluationPeriods: '1'
Statistic: Average
Threshold: '30'
ComparisonOperator: LessThanOrEqualToThreshold
AlarmDescription: Alarm if target instance CPU is underutlized
Period: '120'
AlarmActions: [!Ref 'FleetScalingDownPolicy']
Namespace: 'AWS/ECS'
Dimensions:
- Name: ClusterName
Value: !Ref 'DemoCluster'
MetricName: CPUUtilization
Please checkout the full cloudformation template here. The last but not least, please don’t go crazy on biding price in the spot market,as it already saves 80% cost comparing to on-demand. We usually bid full price on it, because you only pay market prevailing price versus bidding price. Now we are running everything on the spot instance, we will walk through how wrap up work on spot instance 2 minutes termination window.
Enjoy being a “pirate” on AWS! “Take everything you can get and give nothing back.” At least we are smart pirate 🙂
{kind=link}