Read Time 9 mins | Written by: Celeste Shao | Ryo Hang
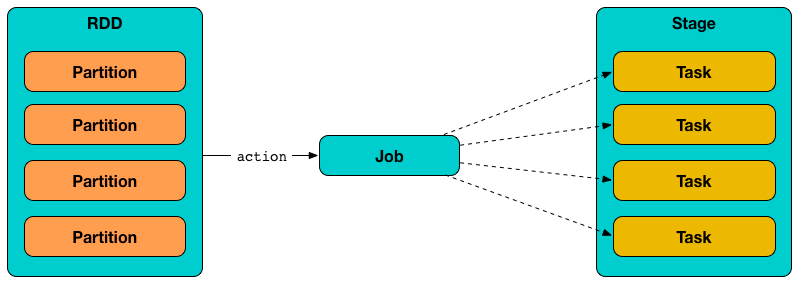
What is Partition in Spark?
Imagine your company is a large e-commerce platform that stores information about customer orders. You have a vast amount of data on millions of orders, including details like order date, customer ID, product purchased, and shipping location.
Now, think of this data as a massive puzzle, with each piece representing a single order. The goal is to complete this puzzle as quickly and efficiently as possible to gain valuable insights and make informed business decisions.
Partitioning in Spark is like breaking this giant puzzle into smaller, manageable pieces or partitions. Each partition contains a subset of the orders, and these subsets are carefully organized based on a specific characteristic, such as the order date or customer location.
Why Partition strategy is crucial?
We could write another blog just to answer this question. Long story short, it is because a well-designed partition strategy will make the Spark program much more efficient!
As an example, let’s say we choose to partition the data by order date for the orders data. Suppose someone in your company wants to know how many orders were placed in a specific month. With partitioning, Spark can quickly identify the relevant partitions and only focus on those, making the query much faster.
It’s like reading a well-organized book, you can check the table of contents then go to the chapter you are interested in and collect the information you need, no need to read the whole book. Imagine how painful it would be to read a book without any table of contents, chapter, or titles, so hard to gather useful knowledge from it, right?
Performance Bottleneck when Export Outputs in Partitions
A well-structured partitioning system in your storage infrastructure can significantly expedite data retrieval. However, it's quite common to encounter delays when exporting output data into the desired partition structure. Naturally, we aim to streamline this process because we don't want the cost and time savings achieved on the reading side to be squandered during the writing phase.
In a recent project, the ASCENDING team encountered a scenario mirroring this challenge while assisting a client in accelerating data export operations within their meticulously designed partition structures for multiple tasks. We will use this client's case as a practical example to share our insights and tips on optimizing Spark partitioning.
repartition VS partitionBy
Before we delve into the heart of the matter, let's clarify and distinguish two crucial methods of partitioning in Spark: repartition and partitionBy. Our aim is not only to demystify these concepts, which often confound many, but also to shed light on their roles as potential troublemaker when clients export Parquet files to an S3 location.
According to Spark Official documentation, here are the definitions of partitionBy and repartition:
partition: Partitions the output by the given columns on the file system.
repartition: Returns a new DataFrame partitioned by the given partitioning expressions (could be either number of partitions or columns). The resulting DataFrame is hash partitioned.partitionBy : This method partitions the output by specific columns on the file system. When exporting data into storage systems like S3, it organizes the data physically into directories or subdirectories based on the distinct values found in the specified column(s).
repartition : On the other hand, repartition is a DataFrame operation that rearranges data within the DataFrame, either by specifying the number of partitions or by choosing specific columns. In the latter case, it ensures that data sharing the same values in the selected column(s) end up in the same partition.
ASCENDING Approach
Let us utilize a particular example to illustrate the steps and methods how ASCENDING analyzed and solved the problem.
In this case, ASCENDING deployed the Spark cluster utilizing the Amazon EKS Kubernetes service, complemented by the JupyterHub feature. This infrastructure offers Data Engineers enhanced runtime visibility into intricate details, such as partition strategies in Spark. Notably, it equips the team with robust capabilities for debugging, troubleshooting, and iterative testing.
Now, let's consider a particular job where writing the output data, totaling approximately 60GB, is expected to take around 2 hours. The data writer and a simplified version of the code are presented below:
// 2 hrs
def saveDatasetWithSomeIdPartitionParquet(dataset: Dataset[Row], s3Path: String): Nothing = {
dataset = dataset.repartition(col("some_id"))
dataset.write()
.partitionBy("some_id")
.format("parquet")
.save(s3Path)
}Analysis: Exploring the Impact of Partitioning in Spark
To investigate the potential impact of partitioning on our data processing job, we initially conducted a test without using any partitioning methods. We replaced the existing data writer with the following simplified Spark writer:
// 18 mins
dataset.write.format("parquet").save("s3Path")
This modification reduced the job's execution time to just 18 minutes. This outcome strongly suggests that the previous slowdown was indeed caused by the partitioning methods (repartition and partitionBy). This test has provided us with valuable insights and serves as an excellent starting point for our analysis.
Before proceeding, it's important to emphasize that we intend to retain the partitionBy("some_id") operation. This operation defines our desired partition structure, which downstream Spark jobs rely on for input data. It is integral to our data organization strategy.
However, the decision regarding whether to retain the repartition operation is more nuanced. Repartitioning in Spark involves an inherent cost due to the data shuffle it induces, leading to a physical exchange of data across partitions. Despite this expense, there are compelling reasons to consider retaining repartitioning, which we will explore further in this blog.
Solution 1: Optimize repartition()
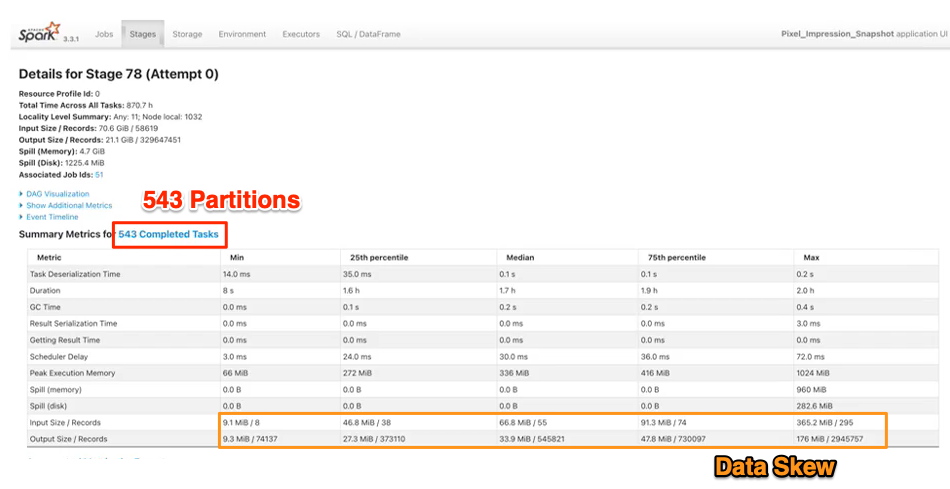
Let’s see what happens if we remove repartition. When data is written to the storage system with the specified partitioning, each distinct value within the some_id column becomes a separate partition directory in the storage system. However, this partitioning is inherently tied to the existing data distribution within the dataset.
To put it into perspective, if we have 543 partitions before writing the data, there will be approximately 543 files for each partition. Assuming there are 100 distinct values in some_id, this translates to a total of 54,300 files (543 x 100) and an average file size of only 1.1 megabytes (60,000 MB / 54,300). The problem with smaller S3 files arises from the way Spark reads data. Spark’s performance is optimized for fewer, larger files. When it encounters many smaller files, it has to open and close connections for each file, leading to a significant overhead and slower processing times.
While dataset = dataset.repartition(col("some_id")) can address the issue of smaller files by ensuring that each partition directory contains only one file, we encounter another challenge—data skew within the dataset. This means that some values in some_id have substantially more data than others. For example, if one partition contains 5 GB of data, Spark will write this entire 5-GB dataset into a single file, leading to potentially extensive processing times.
Our objective is twofold: we aim to eliminate small files while also breaking down the 'large files' into smaller, more manageable ones. To achieve this, we offer the following recommendations:
df.repartition(numPartitions, "some_id")
The parameter numPartitions should serve as an upper bound (though the actual number can be lower) for the desired number of files written to each partition directory. For instance, if the largest partition size is 5 GB, and the recommended S3 file size should fall within the range of 100-500 MB (let’s choose 200 MB in our case), numPartitions would be set to 25 (5,000 MB / 200 megabytes). We also advise clients to calculate this value dynamically in their code rather than hard-coding it to a fixed number.
In addition, to exert greater control over the output file size, we propose the use of the following options:
spark.sql.files.minPartitionNum=1
spark.sql.files.maxPartitionBytes=500mb
These settings offer more precise control over the size of the output files, ensuring that they align with your desired configuration for optimal performance.
Solution 2:Partition Optimization using AQE
From the Spark UI screenshot, we also find another potential improvable area. We can see for this relative large 60 GB dataset, there’s only 543 partitions. Also, we know the client had 50 executors and each has 16 cores. Spark’s official recommendation is that you have ~3x the number of partitions than available cores in cluster, to maximize parallelism along side with the overhead of spinning more executors. Therefore, the optimal number of partitions in this scenario would be 3 x 16 x 50, totaling 2,400 partitions. Considering an average partition size of 60 GB / 2,400 partitions, we arrive at an ideal size of 25 megabytes per partition—a suitable configuration to proceed with.
However, it's crucial to exercise caution when determining the partition count to prevent it from growing excessively, as an overly large number of partitions can introduce parallelism overhead. Fortunately, starting from Spark 3, we have the ability to leverage adaptive query execution (AQE) configurations to better control the level of parallelism.
Here are some AQE configs we suggested:
spark.sql.adaptive.enabled=true
spark.sql.adaptive.coalescePartitions.enabled=true
spark.sql.adaptive.coalescePartitions.parallelismFirst='false'
spark.sql.adaptive.advisoryPartitionSizeInBytes=32m
spark.sql.adaptive.coalescePartitions.initialPartitionNum=2000
Now, let's delve into each of these configurations and provide more comprehensive explanations for their usage and benefits:
-
spark.sql.adaptive.enabled=true: Spark SQL can turn on and off AQE byspark.sql.adaptive.enabledas an umbrella configuration. As of Spark 3.0, there are three major features in AQE: including coalescing post-shuffle partitions, converting sort-merge join to broadcast join, and skew join optimization. We need to make sure this option is enabled since it is required for us to adjust other parameters. -
spark.sql.adaptive.coalescePartitions.enabled: it has to be enabled for the next three configs. Spark will coalesce contiguous shuffle partitions according to the target size (specified byspark.sql.adaptive.advisoryPartitionSizeInBytes), to avoid too many small tasks. -
spark.sql.adaptive.coalescePartitions.parallelismFirst='false': When true, Spark ignores the target size specified byspark.sql.adaptive.advisoryPartitionSizeInBytes, we need to set this config to ‘false’ so that Spark will respect the target size we specified inspark.sql.adaptive.advisoryPartitionSizeInBytes -
spark.sql.adaptive.coalescePartitionSizeInBytes=32m: Spark will coalesce contiguous shuffle partitions according to the target size (specified byspark.sql.adaptive.advisoryPartitionSizeInBytes), to avoid too many small tasks. -
spark.sql.adaptive.coalescePartitions.initialPartitionNum=2000: As stated above, the adaptive query execution optimizes while reducing (or in Spark terms – coalescing) the number of partitions used in shuffle operations. This means that the initial number must be set high enough, in our case we set it to 2000.
Conclusion
Through the implementation of advanced repartitioning techniques and Adaptive Query Execution (AQE), we successfully reduced the average writing time for our client's various jobs by approximately 50%. Given that data exporting is one of the most time-intensive stages, the resulting cost savings have the potential to account for as much as one-quarter to one-third of the total expenses.