Read Time 13 mins | Written by: Ryo Hang

In this post, we will talk about how to implement continuous deployment on Kubernetes Platform using AWS CodePipeline on AWS cloud. If you are interested in CI/CD in ECS, you can refer to CI and CD with AWS CodePipeline, CodeBuild and CloudFormation – Part 1 | Continuous Integration & Continuous Delivery.
We first provide some basic demo YAML code to run a Kubernetes cluster on AWS, then provide detail instruction and example code for you to setup Codepipeline CI/CD to continuous deployment on Kubernetes
Kubernetes vs ECS vs EKS
Kubernetes is a portable, extensible open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. Kubernetes uses persistent entities to represent the state of cluster in .yaml format. Thus, all of the tasks can be managed in a more consistent way, no matter it’s in an on-premise server, cloud computing platform or hybrid cloud environment.
AWS provides Elastic Container Service (Amazon ECS) as a highly scalable, fast, container management service that makes it easy to run, stop, and manage Docker containers on a cluster. ECS components (e.g. services, tasks) can be defined as a .yaml format within the CloudFormation template.
AWS also released Amazon Elastic Container Service for Kubernetes (AWS EKS) in 2018. It’s a managed service that makes it easy for users to run Kubernetes on AWS without needing to stand up or maintain their own Kubernetes control plane.
| ECS | Kubernetest Platform in AWS | EKS | |
| Application Scalability Constructs | Applications can be defined using task definitions written in YAML. Tasks are instantiations of task definitions and can be scaled up or down manually. | Each application tier is defined as a pod and can be scaled when managed by a deployment, which is specified declaratively, e.g., in YAML. | Each application will be defined and scaled in the level of pods and EC2 instances. |
| High Availability | Deployments allow pods to be distributed among nodes to provide HA, thereby tolerating infrastructure or application failures. | Schedulers place tasks, which are comprised of 1 or more containers, on EC2 container instances. | AWS provides the HA of EKS cluster, while developers can enhance the availability of worker nodes by implementing multi-AZ. |
| Interoperability | Amazon ECS is tightly integrated with other Amazon services, it relies on other Amazon services, such as Identity and Access Management (IAM), Domain Name System (Route 53), Elastic Load Balancing (ELB), and EC2. | Kubernetes can be either on on-premise servers, AWS or mixed cloud environment. It can be interacted, but not necessary, with cloud resources | The EKS cluster relies on AWS (including subnet, security groups and IAM) |
| Rolling Application Upgrades and Rollback | Rolling updates are supported using “minimumHealthyPercent” and “maximumPercent” parameters. | A deployment supports both “rolling-update” and “recreate” strategies. Rolling updates can specify a maximum number of pods. | Same as regular Kubernetest platform |
| Disadvantages | ECS is not publicly available for deployment outside Amazon, which means it can not be implemented in a hybrid cloud environment | The installation process is complex (fortunately we have Kops) | Easy to use, but not cost-effective |
Use Kops to create and maintain Kubernetes Cluster in AWS
Kops is a tool which can automate the provisioning of Kubernetes clusters in AWS. Users can either create new AWS resources including security group, subnet and SSH key pair or using existing AWS resources. Kops is a free, open source tool, and users only pay for AWS resources like EC2 instances, NAT gateway, and load balancer. Please refer this article to distribute Kubernetes master and slave servers in AWS, install and configure kubectl. Then try
kubectl get pods
The following result will be returned.

A standard Kubernetes Cluster has one master node and at least one worker nodes. Kubernetes master covers controller-manager, API server, scheduler, and some other functions, while nodes maintain running pods and provide the Kubernetes runtime environment.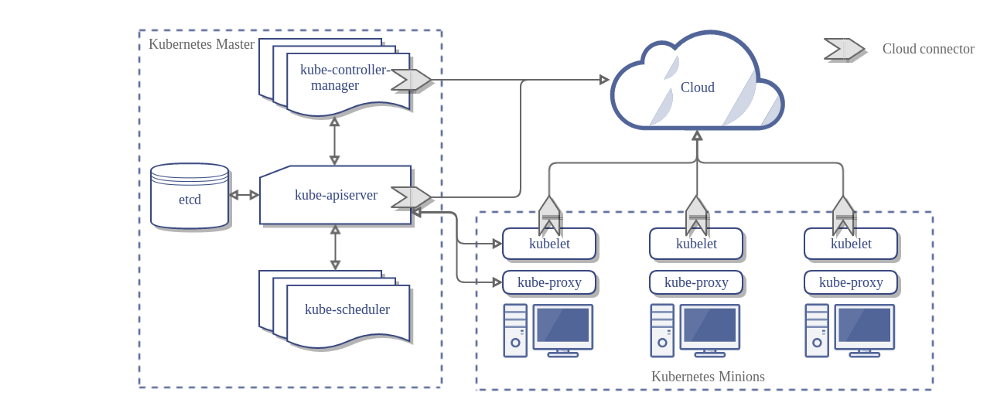
In AWS, one single EC2 instance can work either as a master or node server.
Interact with Kubernetes cluster
To create, modify or delete Kubernetes objects, users need to interact with Kubernetes cluster via Kubernetes API. Kubernetes tool like kubectl is also an option, in that case, the CLI makes the necessary Kubernetes API calls for you.
Kubernetes object(Example)
In Kubernetes, the state of the cluster, including the containerized applications running situation, available resources and applications behave policies, upgrades, and fault-tolerance can be represented by Kubernetes object.
A Kubernetes object is a purpose-oriented, yaml-styled and status-granted concept in Kubernetes system. A typical Kubernetes object can be seen below:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo ${DEMO_GREETING} && sleep 3600']
env:
- name: DEMO_GREETING
value: "Hello Kubernetes!"
Commandline Kubectl
For example, for a developer to describe a particular pod in kubernetes cluster.
kubclt describe pods podA
Kubernetes API
The last command is actually going to send following API request to the cluster, which we can directly invoke.
curl -X GET --header "Authorization: Bearer ${actualToken}" ${HOST_SITE}/api/v1/namespaces/{namespace}/pods/{name}/status
Please refer the document for a full list of Kubernetes API.
Kubernetes Credentials
Users must set up proper credentials before they use kubectl command line or invoke Kubernetes API. In kubectl tool, a set of credentials is stored as Secrets, which is in Kubernetes object format and mounted into pods allowing in-cluster processes to talk to the Kubernetes API.
Run this command to find the name of the secret.
kubectl get secret
Replace $SECRET_NAME with the output from the above command line.
kubectl get secret $SECRET_NAME -o jsonpath='{.data.token}' | base64 --decode
Kubernetes also supports other methods to authenticate API requests including client certificates, bearer tokens, authenticating proxy or HTTP basic auth.
For example, if the flag –enable-bootstrap-token-auth is enabled, then bearer token credentials will be implemented to authenticate requests against the API server. The header Authorization: Bearer 07401b.f395accd246ae52d in HTTP request will take effect.
Continuous Deployment for Kubernetes
In Kubernetes, a Deployment object describes a state in a Deployment object, and the Deployment controller changes the actual state to the desired state at a controlled rate. A typical Deployment object can be found below:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
labels:
app: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo ${DEMO_GREETING} && sleep 3600']
env:
- name: DEMO_GREETING
value: "Hello Kubernetes!"
The deployment of the containerized application in Kubernetes is intrinsically the change from status A to status B in Kubernetes Deployment object.
Continuous deployment is a software development practice where code changes are automatically deployed to production without explicit approval. A typical continuous deployment process for containerized java application running on Kubernetes can be described in the following architecture.
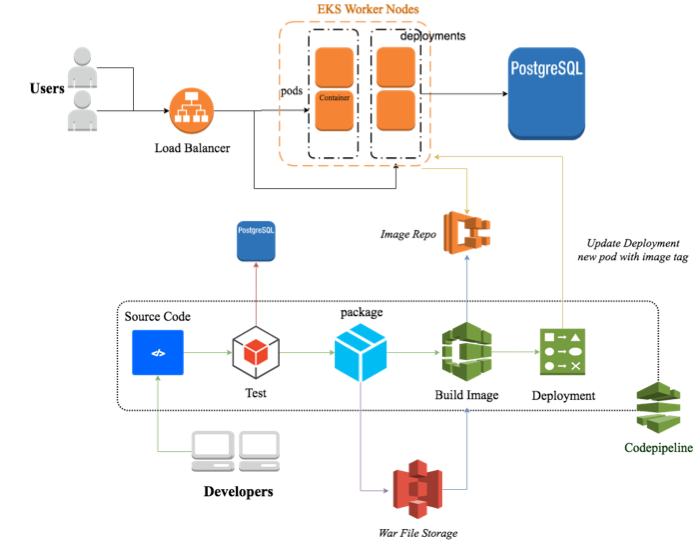
A typical Continuous Deployment process usually contains the following stage:
- Source: Retrieve source code from GitHub or other source code repository.
- Test: Connect to unit test database to run unit test, this stage happens after Build Stage.
- Build: Build .war file, docker image or other types of artifacts and store it to S3, ECR or directly transmit it to next stage.
- Deployment: Deploy the most current version to running application. In this stage, the deployment strategy can be Rolling, Immutable or Blue/Green, which grants the application will have zero downtime for users.
- Monitor: The status of each stage and the health of application will be monitored and alarmed during the whole CI/CD process.
Serverless CI/CD with Codepipeline
Every organization use their favorite tool such as Jenkins or TeamCity to manage continuous integration and continuous delivery. We found Codepipeline is particularly powerful with seamless integration to most of AWS services, on top of that we don’t have to manage infrastructure as Jenkins. We useCodepipeline in the test, packaging and image building stages for entire CI/CD pipeline. CodeBuild a serverless container service that allows running a few Linux commands in a docker container. AWS also provides Lambda function, another serverless service, which invokes a given function in a predefined programming language (e.g. Python, Go, Java).
In the deployment stage, either CodeBuild or Lambda function can be used, which is going to correspond to two interaction methods with Kubernetes cluster, Kubectl tool, and Kubernetes API.
Manually create sample Kubernetes Deployment
In the second part of this article, a new Kubernetes cluster with one slave node server has been created. Create a YAML file named sample_deployment.yaml and its content can be found here.
Then run the following command:
kubectl create -f sample_deployment.yaml
Next
kubectl get pods | grep myapp-deployment
Such a result will be returned
![]()
The pod name can be found in the result, then run
kubectl logs ${POD_NAME}
and you will see “Hello Kubernetes!” at the terminal. After that, we can try to update the environment variable DEMO_GREETING, and this behavior can be regarded as a new version deployment.
kubectl set env deployment/myapp-deployment DEMO_GREETING='Another Hello Kubernetes!'
Immediately run
kubectl get pods | grep myapp-deployment
It can be observed that two pods are terminating while two new pods are being launched, copy the new pod name and then
kubectl logs ${POD_NAME}
“Another Hello Kubernetes!” will be returned, which indicates the completion of deployment.
Deploy Kubernetes pod continuously in CodeBuild
In AWS CloudFormation, we can define a similar step in CodeBuild as following yaml format.
In this demonstration, the environment variable DEMO_GREETING is updated and deployed to the container. It’s a common scenario that the developers want to use the most current version of an image to replace the previous ones in the containerized application, and it’s also recommended that docker image can be tagged by git hash commit from source code e.g. web-api:xxxxxxx. In that case, the same version of the source code, .war file, and docker image will be tagged by the same git commit hash, which makes it easy to track code changeset, troubleshoot and revert back to the previous version.
The command line to update the image is like:
kubectl set image deployment/${DEPLOYMENT_NAME} ${APP_NAME}=${IMAGE_NAME}:${IMAGE_TAG}
Following is a detailed example of updating the environment variable in the containerized application.
Deployment:
Type: AWS::CodeBuild::Project
Properties:
Artifacts:
Type: no_artifacts
Description: update environment variables
Environment:
ComputeType: BUILD_GENERAL1_SMALL
Image: aws/codebuild/standard:1.0
Type: LINUX_CONTAINER
Name: Deployment
ServiceRole: !Ref CodeBuildRole
Source:
BuildSpec: |
version: 0.2
phases:
install:
commands:
- curl -o kubectl https://amazon-eks.s3-us-west-2.amazonaws.com/1.10.3/2018-06-05/bin/linux/amd64/kubectl
- chmod +x ./kubectl
- mkdir -p /root/bin
- cp ./kubectl $HOME/bin/kubectl && export PATH=$HOME/bin:$PATH
- curl -o heptio-authenticator-aws https://amazon-eks.s3-us-west-2.amazonaws.com/1.10.3/2018-06-05/bin/linux/amd64/heptio-authenticator-aws
- chmod +x ./heptio-authenticator-aws
- cp ./heptio-authenticator-aws $HOME/bin/heptio-authenticator-aws && export PATH=$HOME/bin:$PATH
pre_build:
commands:
- mkdir -p ~/.kube
# upload the ~/.kube/config file in S3, then retrieve it from S3 and save as ~/.kube/config
- aws s3 cp s3://example-bucket/config ~/.kube/config
- export KUBECONFIG=$KUBECONFIG:~/.kube/config
build:
commands:
- kubectl set env deployment/myapp-deployment DEMO_GREETING='Another Hello Kubernetes!' --kubeconfig ~/.kube/config
GitCloneDepth: 1
Location: https://github.com/user/example.git
Type: GITHUB
Deploy Kubernetes pod continuously in Lambda function
To implement Lambda function in Codepipeline process, a bearer token should be retrieved and stored according to previous paragraphs. An HTTP request will be made within Lambda function and sent to Kubernetes cluster to trigger a new deployment.
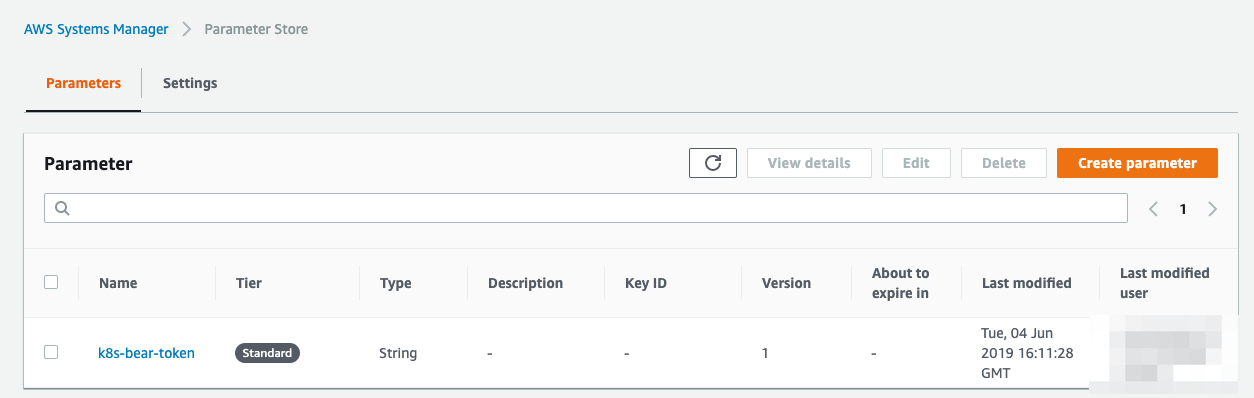
Mask credentials with AWS Systems Manager Parameter
In most of the case, we shouldn’t write credentials or token in plain text. We can use AWS Systems Manager Parameter Store. In this case, the token is named as k8s-bear-token.
Create a role to invoke Kubernetes API
It’s essential that a cluster role binding is created to allow cluster API to be invoked. Create the following file and named it as fabric8-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: fabric8-rbac
subjects:
- kind: ServiceAccount
# Reference to upper's `metadata.name`
name: default
# Reference to upper's `metadata.namespace`
namespace: default
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
Deploy the above role object
kubectl create -f fabric8-rbac.yaml
We can compose a lambda function now. In our case, the host site of Kubernetes cluster (http://localhost if running Kubernetes locally) is stored as environment variable k8s_cluster
import requests
import json
import boto3
import os
client = boto3.client('ssm')
response = client.get_parameter(Name='k8s-bear-token')
url = os.environ['k8s_cluster']+'/apis/apps/v1/namespaces/default/deployments/example-deployment'
headers = {'Content-Type':'application/json', 'Authorization':'Bearer '+response['Parameter']['Value']}
body = {
"apiVersion": "apps/v1",
"kind": "Deployment",
"metadata": {
"name": "example-deployment",
"labels": {
"app": "example"
}
},
"spec": {
"replicas": 2,
"selector": {
"matchLabels": {
"app": "example"
}
},
"template": {
"metadata": {
"labels": {
"app": "example"
}
},
"spec": {
"containers": [
{
"name": "example-container",
"image": "busybox",
"command": [
"sh",
"-c",
"echo ${DEMO_GREETING} && sleep 3600"
],
"env": [
{
"name": "DEMO_GREETING",
"value": "Another Hello Kubernetes!"
}
]
}
]
}
}
}
}
This lambda can be invoked in the deployment stage of CodePipeline, with bear token stored in AWS System Parameter and cluster host site stored as an environment variable to keep security. Developers are able to define customized parameters in CodePipeline event, in case that deployment commands contain a commit hash, time or other variables
Comparison Between CodeBuild and Lambda
Both CodeBuild and Lambda function can be implemented in the deployment stage, the comparison between them can be seen below
| CodeBuild | Lambda | |
| Security | Medium | Strong |
| Difficulty | Easy | Medium |
| Flexibility | Medium | High |
| Efficiency | Low | High |
| Overall Score | ⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️⭐️ |
Case Study
We have applied the above CI/CD strategy to one of our customers. Our continuous deployment process saved more than 80% of the time spent on product release for TOKENEED, which helped them get a quicker return on the investment. In addition to that, ASCENDING also helped TOKENEED standardized application deployment process, in reinforcing the consistent deployment behavior in each product release. TOKENEED also benefitted from this well-designed architecture for its security, high-availability, and stability. Besides, each deployment process was tagged by a unique hash code, which made it easy to trace back to the previous version of production with zero downtime for customers. Here is the full case study file.
Don’t hesitate to contact us if you have any question about our blog and service!
