Read Time 18 mins | Written by: Mythri.S | Celeste Shao

Amazon DynamoDB is a NoSQL database service provided by Amazon Web Services (AWS) that allows storing and retrieving data in a flexible, scalable, and high-performance manner. The design process is a lot different from traditional relational database design. One popular way to use Amazon DynamoDB is through a single-table design with multiple entities.
In this post, we will talk about a standard DynamoDB design process from The DynamoDB book. While Amazon DynamoDB provides us with great performance, scalability, and other benefits, the design and implementation are not straightforward. We will use three different use cases to illustrate our design practice at the end.
The Setup
The following design process will utilize a simple e-commerce website example to illustrate the design process which contains Users, Orders, Reviews, Products, and Categories information.
Identify the Entities and Relationships
The first step in designing the Amazon DynamoDB table is identifying the entities we need to store and their relationships. Users can have multiple orders and reviews, and categories can have various products.
|
Entity |
PK |
SK |
|
Users |
USER#<UserName> |
USER#<UserName> |
|
Orders |
USER#<UserName> |
ORDER#<OrderId> |
|
Categories |
CATEGORY#<CategoryName> |
CATEGORY#<CategoryName> |
|
Products |
CATEGORY#<CategoryName> |
PRODUCT#<ProductName> |
|
Reviews |
USER#<UserName> |
REVIEW#<ReviewId> |
|
Entity |
GSI1PK |
GSI1SK |
|
Orders |
ORDER |
STATUS#ORDERDATE |
|
Reviews |
PRODUCT#<ProductName> |
REVIEW#<ReviewId> |
Entity Relationship Diagram:
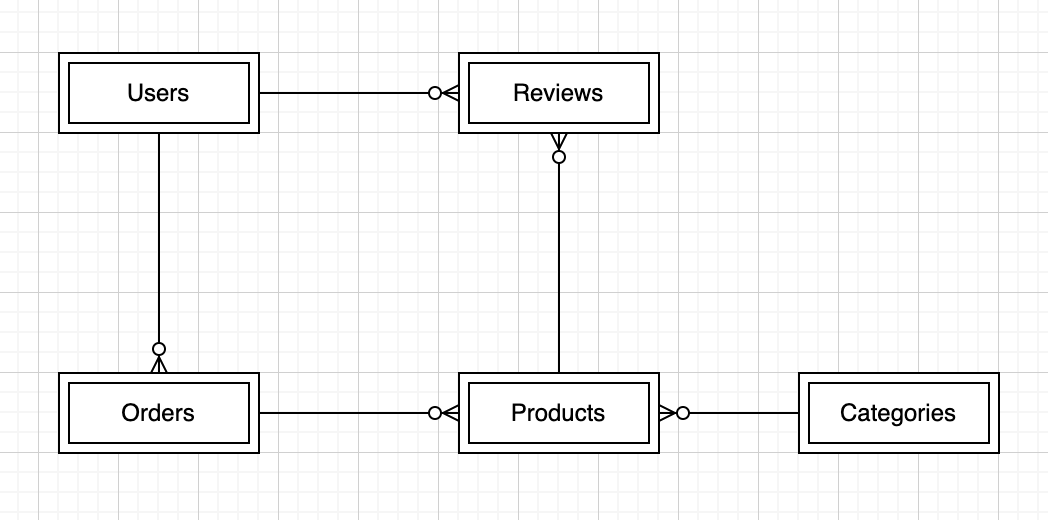
Define the Access Pattern
We should define the access patterns that we need to support. For example, we need to retrieve all orders for a specific user, retrieve all reviews for a particular product, or retrieve all products in a specific category.
We always encourage you to maintain a list of access patterns for each project or utilize annotation to generate that automatically. Here is the sample for your reference.
|
|
Access Patterns |
Key Condition |
||
|
Users |
1 |
Get user |
By Username |
pk=USER#<username>, sk = USER#<username> |
|
2 |
Get all users |
|
Use GSI2 pk=” USER” |
|
|
products |
3 |
Get all products |
|
Use GSI2 pk=” PRODUCT” |
|
4 |
Get products |
By category |
pk = CATEGORY#<categoryname> Sk Begins with PRODUCT |
|
|
|
5 |
Get product |
By productname |
Use GSI2 pk=” PRODUCT” sk Begins with #PRODUCT<productname>
|
|
orders
|
6 |
Get orders |
By username |
pk=USER#<username>, sk Begins with #ORDER |
|
7 |
Get all orders |
|
Use GSI2 pk=” ORDER” |
|
|
8 |
Get orders |
By Range of orderid |
Use GSI2, pk=” ORDER”, sk Between |
|
|
9 |
Get order |
By daterange |
Use GSI1 pk=”#ORDER” sk Between |
|
|
10 |
Get order info |
By orderrid |
Use GSI2, pk=” ORDER”, sk = ORDER#<orderid> |
|
|
reviews |
11 |
Get reviews |
By username |
pk=USER#<username>, sk Begins with #REVIEW |
|
12 |
Get all reviews |
|
Use GSI2 pk=” REVIEW” |
|
|
13 |
Get review |
By reviewid |
Use GSI2, pk=” REVIEW”, sk = REVIEW#<reviewid> |
|
|
14 |
Get reviews |
By product |
Use GSI1 pk=PRODUCT#<productname> Sk begins_with REVIEW |
|
|
Category |
15 |
Get all categories |
|
Use GSI2 pk=” CATEGORY” |
Determine the Key Schema
Based on the access patterns and entities, determine the key schema for the DynamoDB table. In this case, we could use the following key schema.
The partition key could be the entity type, for ex: the user, as it is the parent entity for orders, and similarly, the category is the parent entity for products. This would allow us to retrieve all items of a specific entity type quickly.
Sort Key
The sort key could vary based on the access pattern. For example, if we want to retrieve all orders for a specific user, the sort key could be the order ID. On the other hand, if we want to retrieve all products in a particular category, the sort key could be begins_with product.
Define the Attributes
Define the attributes we need to store for each entity. For example, the attributes of the USER entity are Username, email, address, CreatedAt, and Type.
For the CATEGORY entity CreatedAt, Status, ProductId, Type, Description, and OrderId are attributes.
Create the Table
Created the DynamoDB table with the chosen key schema and attributes.
Define the Secondary Table
Besides the primary key, we must define secondary indexes to support different access patterns. For example, the GSI1 index is defined with GSI1PK as the partition key and GSI2 as the sort key to retrieve all reviews for a specific product and get the order by status, and GSI2 is defined with Type as the partition key and sk as a sort key to get all users, products, categories, and reviews.
Let's take a look at how we solve those three classic use cases:
Use Case 1:
The Problem:
It would be challenging to query an attribute by its value from the table directly, as Amazon DynamoDB does not allow queries by non-key attributes, and it requires a partition key as a required clause. So, for example, we cannot query "find user info by UserName.”
The problem with not being able to query users by UserName is that it can make retrieving specific data from the table based on a UserName challenging. Instead, you would need to perform a full table scan, which can be slow and resource-intensive, especially as the table grows more prominent.
The Solution:
There are multiple ways to achieve this problem.
- We can get user info by UserName by specifying the PK and SK values that match the desired user( PK=USER#<UserName>, SK = USER#<UserName> ). Here PK and SK are Partition Key and Sort Key for the table. Following is the layout for the orders-users-products table.
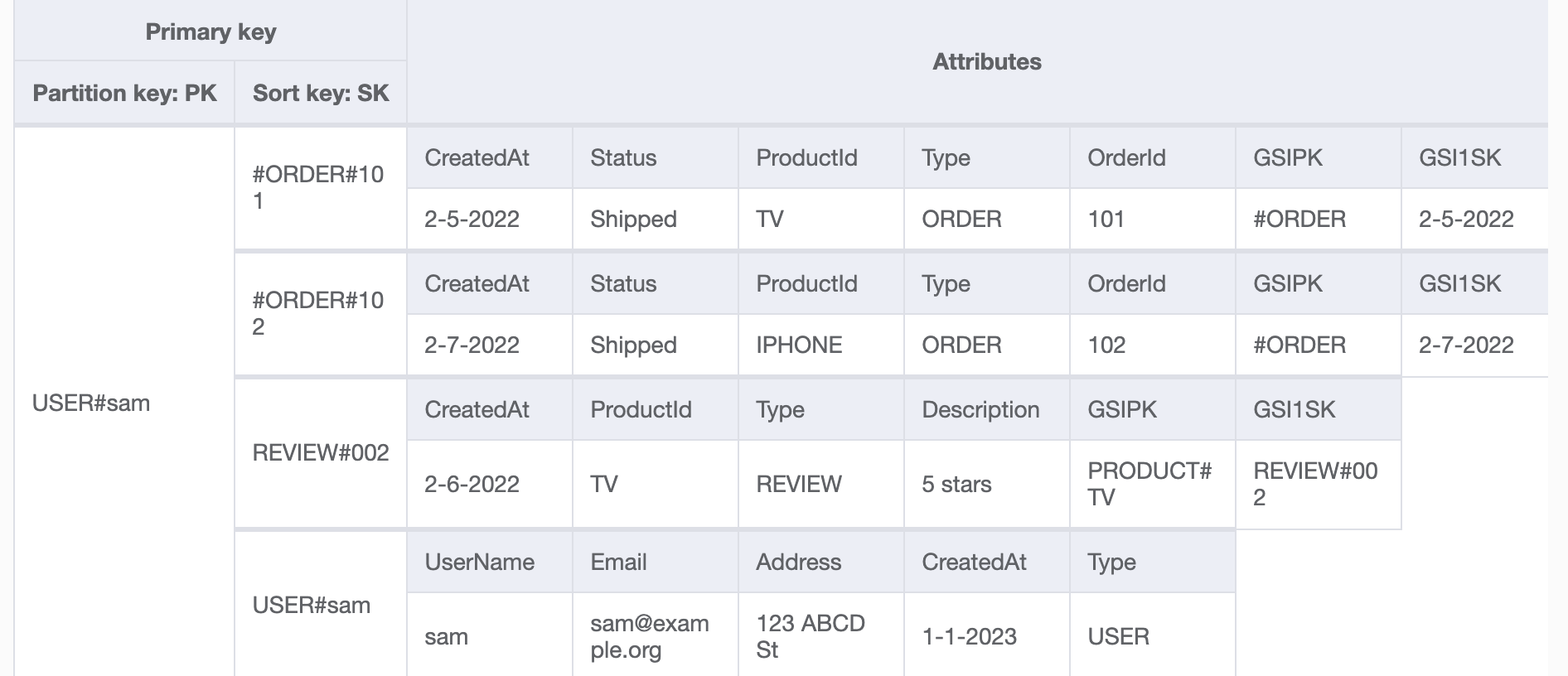
- Another possible solution is to use a secondary index to store UserNames as a partition key.
A secondary index is a data structure that queries a table using an alternate partition key rather than the table's primary key.
For example, create a secondary index on the UserName attribute and then use it to efficiently retrieve all items with a given UserName.
The Result:
The use case is from social media platforms like Twitter or Instagram. First, users create an account with a unique UserName that identifies them. Then the platform members can search for them using their UserName and view their profile, including their bio, profile picture, and content. To retrieve this information, it requires the UserName of the user whose data is asked for, which allows the application to pull and display the relevant information to the user.
Use Case 2:
The Problem:
If we can't efficiently query orders by the range of order IDs, we may have to scan the table to find the necessary data. However, scanning the table to retrieve data can increase latency and slow our application's performance, which leads to increased costs and difficulty scaling our application.
The Solution:
To get all orders for a specific user by using PK as the partition key and SK as the sort key of the base table (pk=USER#<username>, SK Begins with #ORDER) and create a global secondary index(GSI2) with Type as the partition key and SK as the sort key so that we can query all orders by a range of orderId’s (GSI2 pk=” ORDER,” SK Between). Following is the global secondary index(GSI2) for the orders-users-products table.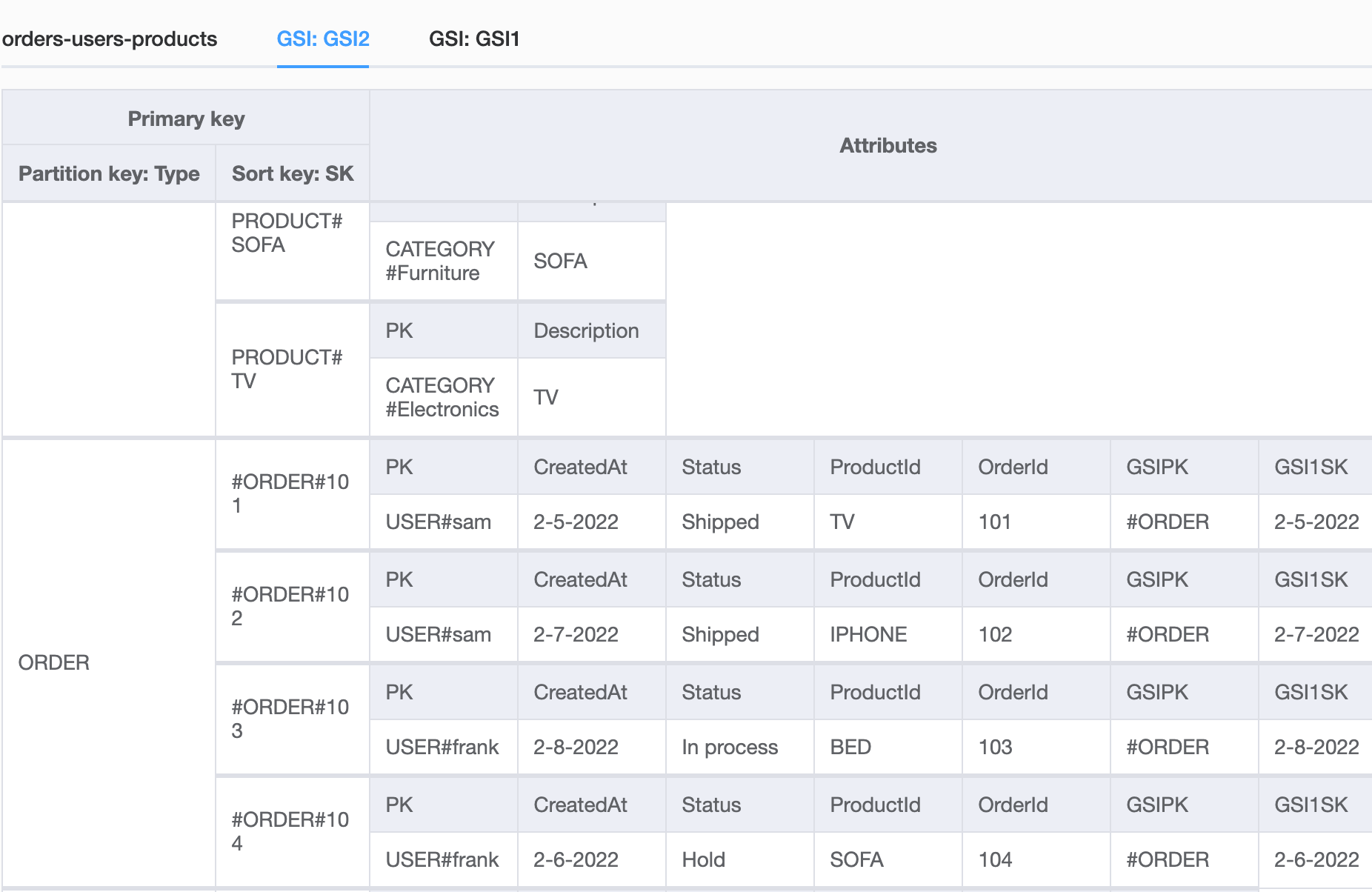 In this scenario, we can query to global secondary index(GSI2), which has the Type as the partition key and SK as the sort key to get all orders by the range of ids or get all products or get all reviews or get all categories, etc
In this scenario, we can query to global secondary index(GSI2), which has the Type as the partition key and SK as the sort key to get all orders by the range of ids or get all products or get all reviews or get all categories, etc
The Result:
For example, an application that needs to sort orders based on a range of order IDs, such as a food delivery platform like Grubhub or DoorDash.
When a customer orders food through one of these platforms, the order is assigned a unique identification number or order id. The order id allows the platform to track the order's status, communicate with the restaurant, and give a delivery driver to pick up and deliver the food.
We may need to sort orders based on the range of order IDs to optimize the delivery process and ensure timely delivery. For example, it might group all orders with IDs in the range of 1000-1999 and assign them to drivers working in a specific geographic area, which allows the drivers to efficiently pick up and deliver multiple orders in the same area, reducing the amount of time and resources required for delivery.
Use Case 3:
The Problem:
If we use a date as the partition key, we may end up with unevenly distributed data across our partitions; this can lead to partition hotspots, where some partitions have more data than others, impacting performance. In addition, if we want to retrieve data from a specific date range, we may need to query multiple partitions, which can be time-consuming and inefficient.
The Solution:
To get all orders for a specific date range, create a global secondary index(GSI1 )with attribute (GSI1PK )as the partition key and attribute (GSI1SK )as the sort key to query all orders by a date range (Use GSI1 PK=”#ORDER” SK Between). Following is the global secondary index(GSI1) for the orders-users-products table.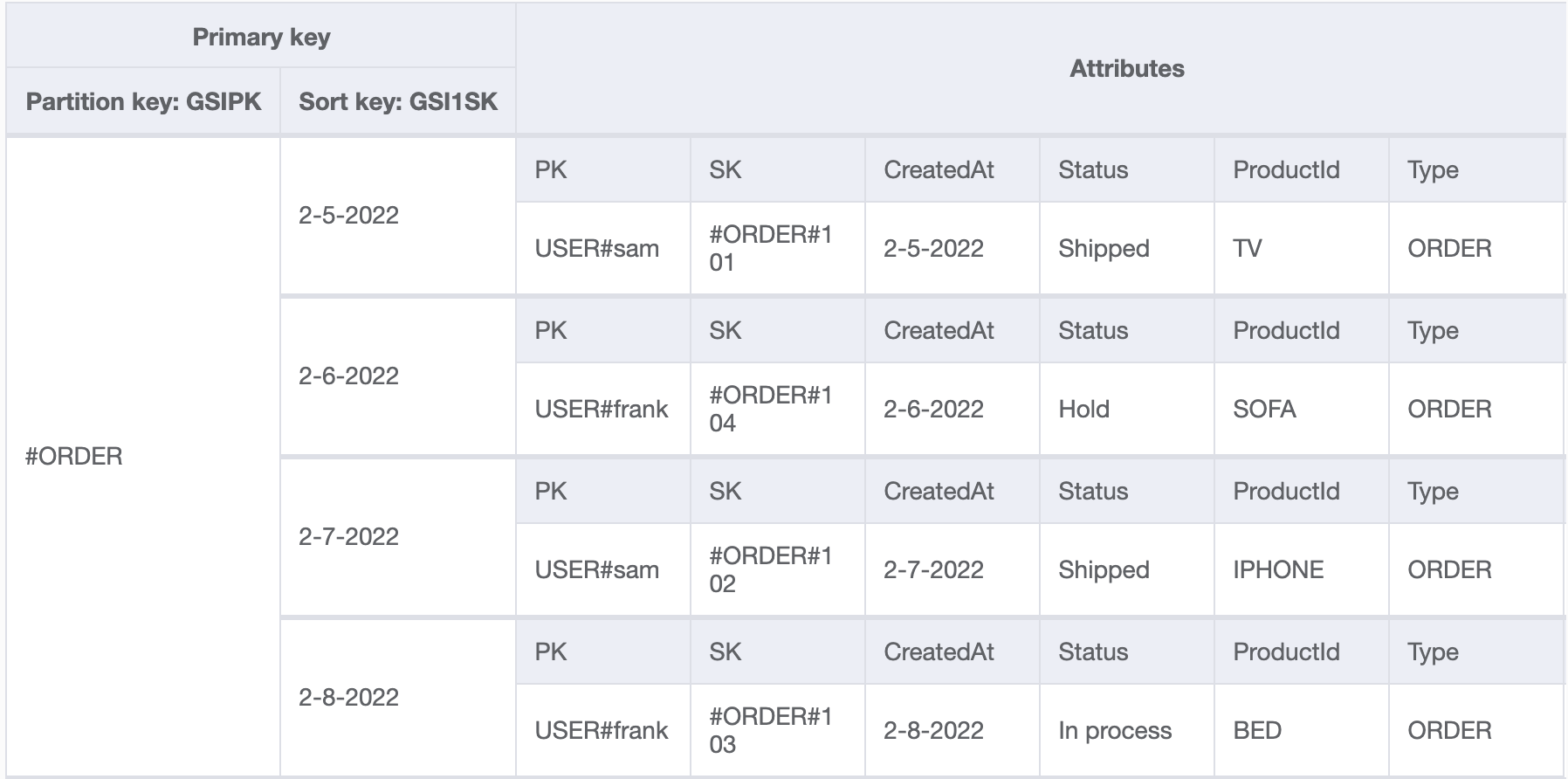 In this scenario, we can query to global secondary index(GSI1), which has GSI1PK as the partition key and GS1SK as the sort key to get all orders by the date range or get all reviews by product.
In this scenario, we can query to global secondary index(GSI1), which has GSI1PK as the partition key and GS1SK as the sort key to get all orders by the date range or get all reviews by product.
The Result:
For instance, we are designing a Amazon DynamoDB table for the theme park to store data about park attendance over time. Initially, we might consider using the date of each park visit as the partition key, since it's a natural way to organize the data and could be useful for queries that filter by date. If Theme parks experience a surge in attendance during certain holidays or special events, they could end up with a large number of park visits all hitting the same partition at once. This could lead to hot partitions, which could cause performance issues and limit the scalability of the DynamoDB table. However, to avoid this problem, we might consider using a different partition key that would distribute the data more evenly across multiple partitions. One option could be to use a combination of park ID and date so that each partition would contain data for a specific park on a specific day. This would help to distribute the data more evenly across multiple partitions, reducing the likelihood of hot partitions and improving the scalability and performance of the DynamoDB table. Another option could be to use a unique visit ID as the partition key, which would distribute the data evenly across multiple partitions and allow for efficient queries based on individual park visits.
We hope you enjoyed the post. Just to recap, while Amazon DynamoDB offers us high performance, availability, scalability, etc, it requires discipline to follow the design process to consider all the access patterns. We highly recommend dev team maintain a list of access patterns either through manual or automation processes.
Useful Resources:
1. Amazon DynamoDB Workbench for the table design - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/workbench.html
2. The Amazon DynamoDB book By Alex Debrie - https://www.dynamodbbook.com/
3. Access Pattern Worksheet. Sample here.