Read Time 8 mins | Written by: Celeste Shao | Ryo Hang
When confronted with a resource-intensive Spark job, people often find themselves uncertain about where to begin their optimization efforts. Indeed, fine-tuning Spark performance is a task that demands the expertise of experienced professionals and a significant investment of time and effort. However, are there strategies that are both straightforward to implement and remarkably effective? Drawing from ASCENDING’s extensive experience in Spark projects, we have discovered that broadcasting is one such strategy.
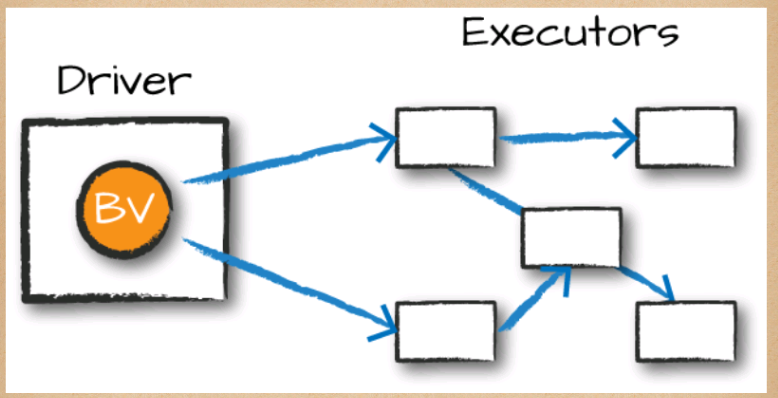
Configuring SparkUI within JupyterHub on Amazon EKS Kubernetes provides a straightforward way to assess the influence of broadcasting on Spark program performance.
Before delving deeper into broadcasting, let me illustrate its efficacy with a typical use case:
Imagine a nationwide retail chain tasked with daily data collection, encompassing sales transactions and customer details, all stored within a distributed cluster. Their objective is to pinpoint high-value customers among recent transactions, a critical analytical task.
Now, the company wants to perform a critical analysis task (a Join): matching customer information with recent transactions to identify high-value customers who made significant purchases in the last quarter.
Join: Initially, they used the standard Join (default to Sort-Merge Join), which took roughly 30-40 mins to complete due to extensive data shuffling and network overhead in a large transaction dataset.
Broadcasting Join: Switching to Spark broadcasting join, they broadcast the smaller customer dataset to all worker nodes, facilitating efficient in-memory joins which only took 5-10 mins to complete.
What is Broadcasting
The Spark UI screenshot presented below illustrates a DAG (Directed Acyclic Graph) depicting the Sort-Merge Join operation. The Exchange step, highlighted in red and commonly referred to as "shuffle," is a resource-intensive process that places substantial demands on computational resources. Shuffling is inherently costly, involving disk I/O, data serialization, and network I/O. For a more in-depth understanding of shuffle, you may find this blog informative.
Since Spark 2.3, Sort-merge Join is the default join strategy, and shuffle would be involved in every Sort-merge Join. Essentially, the most straightforward approach to mitigating the expenses associated with shuffle is to devise a strategy that bypasses it entirely. This is precisely what broadcasting accomplishes.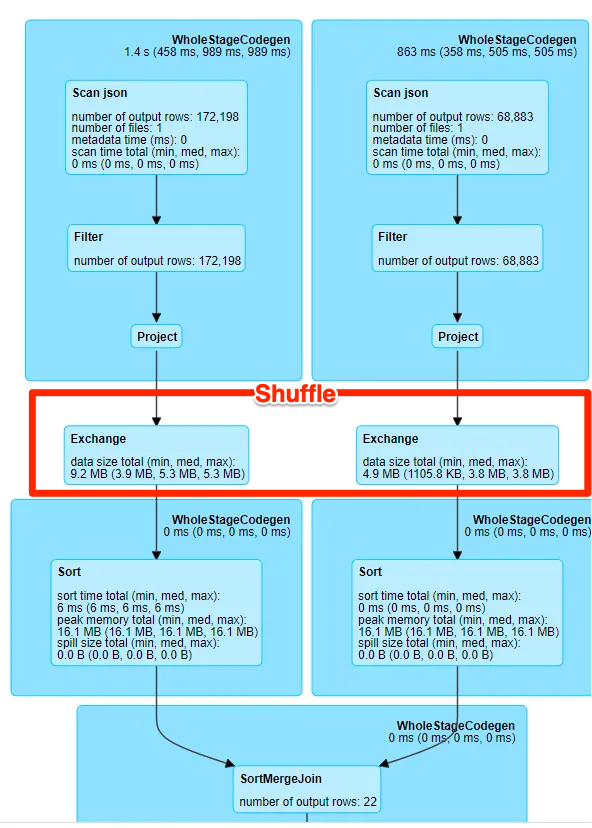
For the same join operation, but broadcasting takes a different approach. It leverages the fact that one of the datasets is small enough to fit entirely in memory, making it ideal for broadcasting to all worker nodes. This means that instead of costly data shuffling, the smaller dataset is sent just once to all nodes, greatly reducing network overhead and computational complexity. As a result, broadcasting can significantly expedite join operations. As you may found from this screenshot, there’s no shuffle involved in a BroadcastHashJoin.
ASCENDING Tips
Now we learned what is broadcast and why it could make joining more efficient. Next, let’s see how we should use it in real cases. Here is a simple example of how we generally use broadcast in the Spark code.
df_big.join(broadcast(df_small), "some_id")While I mentioned that broadcast is a relatively straightforward method, still there are several important details you may want to be aware of.
When to Enable or Disable autoBroadcastJoinThreshold?
Spark 2.0 introduced autoBroadcastJoinThreshold which is a configuration parameter in Spark that determines the maximum size of a DataFrame that can be broadcasted. The default value is 10MB ( 10485760 bytes). If a DataFrame is smaller than this threshold, Spark will automatically apply a broadcast join.
// if the size of df_small < autoBroadcastJoinThreshold, df_small will
// be broadcasted automatically
df_big.join(df_small, "some_id")This sounds like a nice setting, but be careful not to get too rely on it!
If you set autoBroadcastJoinThreshold too high, Spark will attempt to use the broadcast join optimization for even relatively larger tables. This can lead to excessive memory usage as Spark tries to broadcast larger datasets to worker nodes. It may also cause out-of-memory errors if the dataset to be broadcasted exceeds the available memory on the worker nodes.
Conversely, if you set autoBroadcastJoinThreshold too small, Spark may not use the broadcast join optimization even when it could be beneficial. As a result, Spark may perform unnecessary data shuffling operations, leading to increased network and computational overhead.
Ascending recommends the explicit use of broadcast in your code so that you retain full visibility into which datasets are being broadcasted. If you prefer to have precise control over broadcast behavior, you may consider disabling autoBroadcastJoinThreshold as follows:
// disable autoBroadcastJoinThreshold
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)Dealing with Broadcast Timeout
It's essential to be aware that the maximum broadcast size is currently limited to 8GB. This constraint becomes particularly crucial when working with extensive datasets.
Attempting to broadcast datasets exceeding this size constraint can potentially trigger broadcast timeout errors, leading to issues like the following:
java.util.concurrent.TimeoutException: Futures timed out after [300 seconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223)
at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:190)
at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53)In scenarios where such errors occur, it's advisable to consider increasing the value of spark.sql.broadcastTimeout (with a default setting of 300 seconds). This configuration parameter governs the timeout duration, in seconds, for the broadcast wait time during broadcast joins. It's a crucial factor to consider, especially when dealing with larger broadcast datasets.
Additionally, exercise caution and be mindful of both the driver's and the executor's memory capacities to prevent potential Out-of-Memory (OOM) errors.
Troubleshooting Out-of-Memory(OOM) with Iterative Broadcast
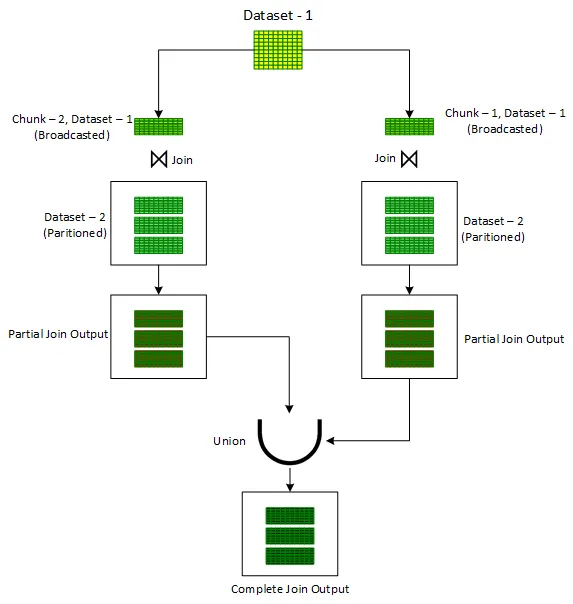
One of the inherent limitations of broadcasting arises when dealing with datasets too large to be accommodated within memory, potentially leading to OOM issues on executors or the driver. To address such scenarios, the 'Iterative Broadcast' technique offers a solution. This approach involves breaking down one of the input datasets, preferably the smaller one, into multiple smaller chunks, each of which can be broadcast without straining system resources. These smaller chunks are then incrementally joined with the unaltered input dataset using the standard 'Broadcast Hash' Join. The outputs from these iterative joins are successively combined using the 'Union' operator to generate the final output.
One method to partition a dataset into smaller chunks is by assigning a random number within the desired range of chunk IDs to each record in the dataset, creating a new column called 'chunkId.' With this column in place, a for loop is initiated to iterate through the chunk numbers. During each iteration, records are filtered based on the 'chunkId' column corresponding to the current chunk number. The filtered dataset is then joined with the unmodified input dataset using the standard 'Broadcast Hash' Join to obtain a partial joined output. This partial output is subsequently merged with the previous partial results. After the loop completes its iterations, the result is the overall output of the join operation applied to the two original datasets.
Conclusion
For relatively intricate Spark jobs, broadcasting emerges as perhaps the most efficient and straightforward optimization technique available. In a recent example, the implementation of broadcasting alone allowed us to circumvent approximately 80% of data shuffling operations, resulting in a remarkable reduction of the total job duration by half.